
The 3 Key Variations of Linear Regression


The first predictive model built in any project is typically a regression. The mother of all “white-box models,” a linear regression provides a straightforward implementation and interpretation. It’s clear for us to see which variables have a large influence on our target and we can also use statistical tests to check the significance of these coefficients. Following inspiration from Occam’s Razor, that “entities should not be multiplied beyond necessity”[1], it makes logical sense to build up in complexity in our models.
There are 3 methods of linear regression that are important to keep in our analysis toolbox. This article aims to cover them all in detail, from their methodology and design to how they are each unique and effective.
Ordinary Least Squares (OLS)
The Ordinary Least Squares or OLS model is the fundamental method for linear regression and is typically the one described or referred to when a paper or project mentions carrying out a regression. The sklearn LinearRegression() function calls an OLS model by default, as does R’s lm() function.
The OLS model aims to find the linear estimate that minimises the sum of squares of the residuals, calculated as the Euclidean distance between the datapoint and the estimate. This is graphed in the 2-Dimensional setting below.

In a higher dimensional setting, this line transforms to a hyperplane with dimension=D-1, where D is the dimension of the datapoints (number of explanatory variables).
Mathematically the OLS method is calculated as the following function, which is the formula for the sum of square of residuals.
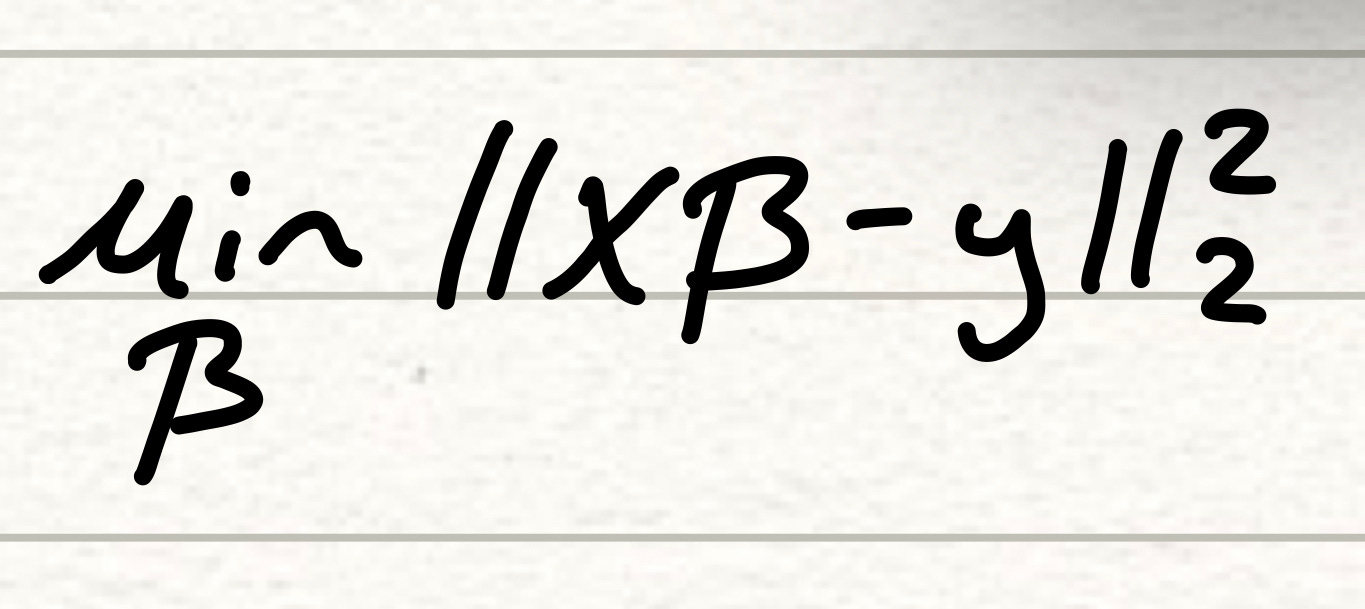
The solution for the OLS method can be calculated in close form and is done so by expanding the formula above, differentiating and calculating beta after setting the differential equal to 0, since we know the sum of square of residuals function is a convex one.
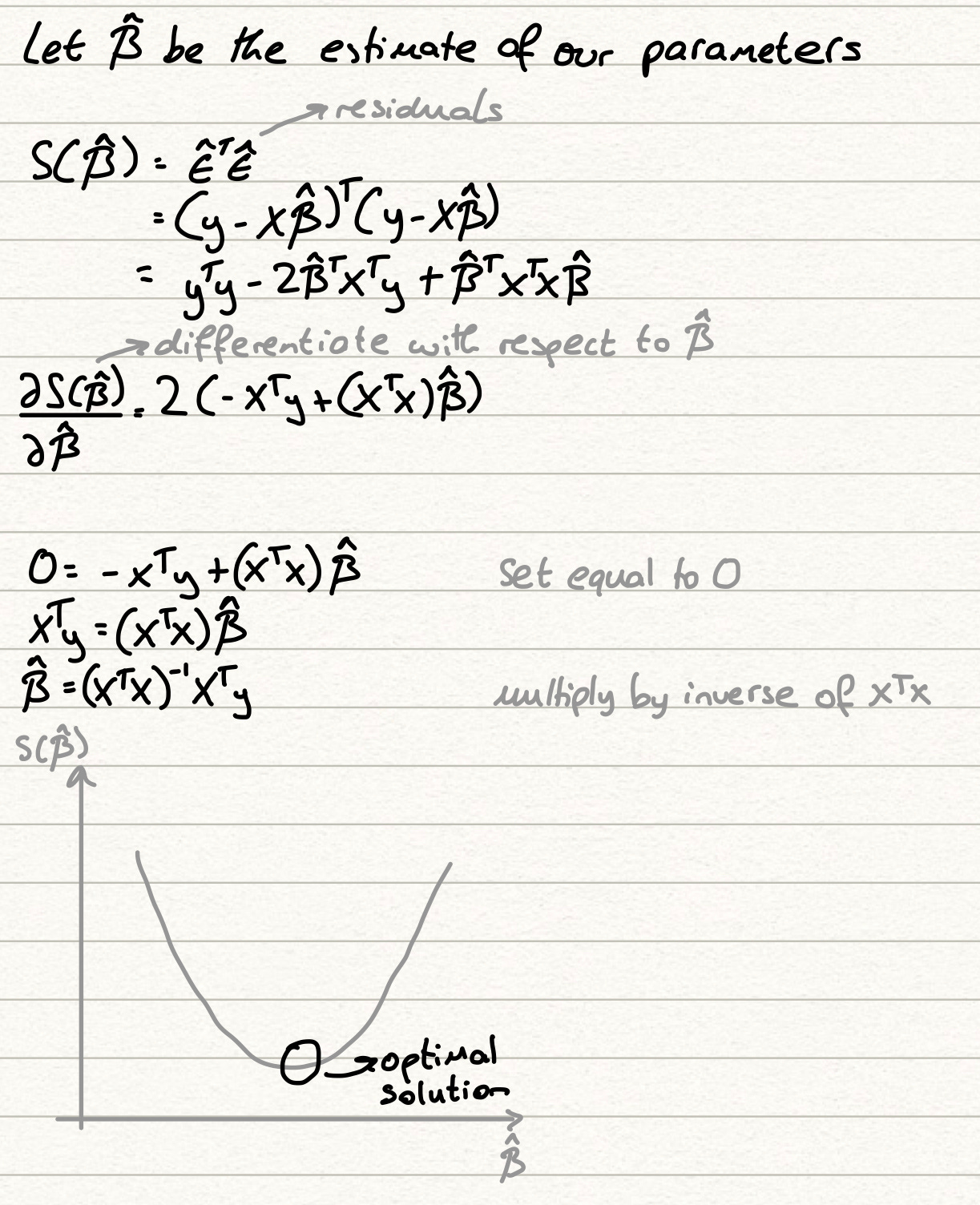
So how does any of this translate into an applicable scenario? Well, the fact that our solution is closed form (essentially this means it can be calculated exactly and we don’t require any form of numerical methods to estimate the solution) means that performance is generally quite fast and interpretable. Regressions are called “white box models” due to the fact that we can see all the calculations they make in order to arrive at a solution and the above proof displays that. This transparency in calculations is also reflected in the output, where typically, in addition to our standard error figure, a regression provides us with coefficient values (beta_hat values) and p-values to check the significance of these values. This helps us easily identify the variables that are key predictors of our target and immediately proposes new research that we can conduct into why certain variables are highly influential and why others aren’t.
Ridge Regression
The Ridge Regression is the first of two shrinkage methods that we’re covering in this article and it’s named as such because the goal of this model is to shrink the estimates of our coefficients towards 0. The benefit of this is that we create more simple and sparse models (those with fewer parameters) and this is useful because it helps us truly isolate important variables and discard those that don’t aid in our investigations.
The way that these two shrinkage methods accomplish this is by adding an additional penalty term to the loss function calculation. Finding the lowest loss is now a balance between the closeness of the estimate to the target value and the size of each respective coefficient. Coefficients that are not proportionally contributing towards reducing the OLS loss relative to their size begin to shrink towards 0 since their size cannot be justified by the model. This behaviour can be summarised in the new loss function below.
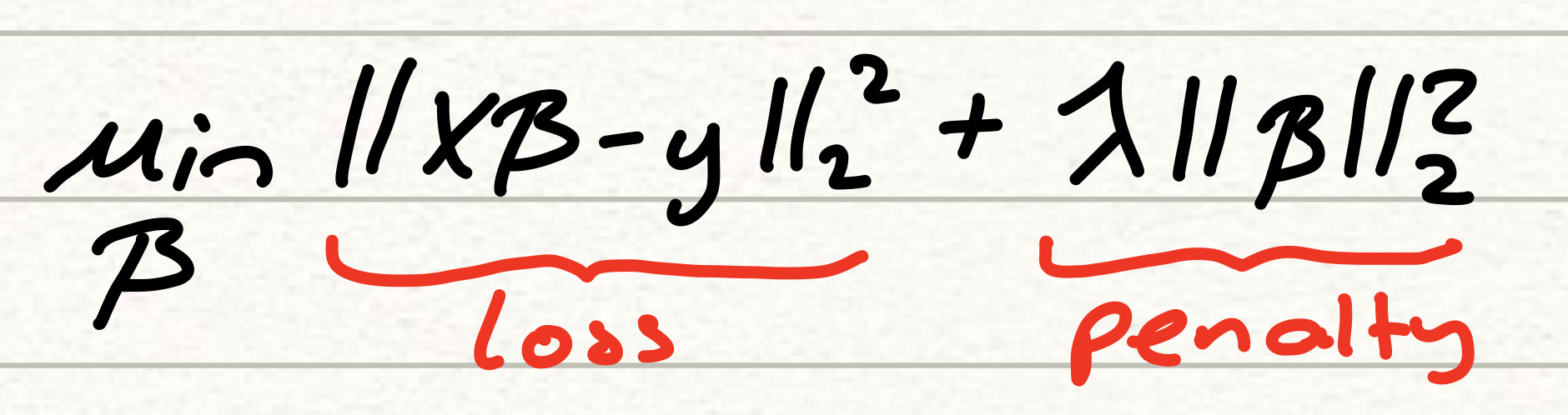
An added benefit to this “isolation” of key variables is that, shrinkage methods tend to perform slightly better than the standard OLS model. Their accuracy on training data is usually lower due to the addition of the penalty parameter, but the priority for us when evaluating any models we built is in its ability to generalise, and both ridge and lasso tend to do that fairly well. Simpler models find it easier to avoid overfitting and that helps to generalise to unseen data.
You’ll also notice that there is a lambda variable within our penalty term. This is called the tuning parameter and essentially dictates how this balance between the loss and penalty is distributed. When lambda = 0, our model will behave exactly as the previous OLS method and too small a value of lambda will lead to a model too complex that might overfit our data. Too high a lambda value and our model will focus purely on the penalty term and all variables will shrink towards 0, impacting both the performance of the model and out interpretation on the predictability of the explanatory variables. Selecting a good value for lambda is therefore crucial.
Lasso Regression
Lasso is less a strict regression and more a feature selection tool that can be applied to a variety of regression methods, including OLS and logistic regression. Formulaically, the lasso model looks very similar to the ridge model, but with one key difference -> instead of calculating the squared value of our parameters in the penalty term, lasso uses the absolute value of the coefficients.

The difference in behaviour between lasso and ridge regression is that whilst in ridge coefficients tend to shrink towards 0, in lasso these coefficients become exactly 0. We’ll cover exactly how this happens in the next article, but the main benefit of this is that we can now use lasso as a form of exact feature selection. The variables whose coefficients are exactly 0 can be immediately discarded from the model since they do not provide any predictive ability towards the target. This helps us clean up our model and keep the focus on the variables that have a clear association.