
ML 101 - Linear Regression

This is article #2 in the “ML 101” series, the purpose of which is to discuss the fundamental concepts of Machine Learning. I want to ensure that all the concepts I might use in the future are clearly defined and explained. One of the most significant issues with the adoption of Machine Learning into the field of finance is the concept of a “black box.” There’s a lot of ambiguity about what happens behind the scenes in many of these models, so I am hoping that, in taking a deep-dive into the theory, we can help dispel some worries we might have about trusting these models.
Introduction
Regression is a machine learning task where we have a real-valued outcome in a continuous sub space. Basically, this means that our outcome is a continuous variable, but that it is usually confined to some sort of range.
Examples of regression include age estimation, stock value prediction, temperature prediction.
Mathematically, we can represent this as follows:

The R is the set of all real numbers. This includes all natural numbers, integers, rational and irrational numbers.
So in linear regression, we take a set of inputs, which we represent as X and attempt to match these to their respective continuous value outputs, which we call y. We can represent this as a tuple {X, y}.
Input variables consist of a collection of features, each of which represent a unique observation about our output (a “feature” of the output if you will). As an example, 3 features — weight, height and gender might be used to predict life expectancy.
The number of features in a dataset is also called the dimensionality of that dataset.
In univariate linear regression (regression with just one explanatory variable or feature), a linear regression model is created through a straight line estimation of our outputs. From graph theory, we know this line will take the form y = mx + c, where m is the gradient of the line and c is the y-intercept. In ML theory, we convert this into an estimation function using w’s or theta’s, which represent our weights.
The above information is summarised in the following image:

Weights are determined by the model, so they are intrinsic parameters. They can be thought of as our model assigning a “relevance figure” to each variable as to how much it relates to the output. The higher the weight, the more influence that feature has on the model output and the better descriptor it is therefore of said output.
Our learning algorithm will take all of these components, the training set, the model h that we provide and the solution space that contains all possible values of our weights, and find the solution s* that minimises a cost function. s* is essentially an array which contains a value for each weight that provides us with an optimal solution.
Deriving the Cost Function
The cost function is our performance metric from the definitions of machine learning we declared in the previous article. The cost function will compare the model output with the actual outputs. So our linear regression model will cycle through a series of weight combinations to find that combination that returns the lowest cost function.
In order to derive a cost function, we can begin by considering how to measure the closeness of the fit. We want to find out how close our estimated value is to actual value.
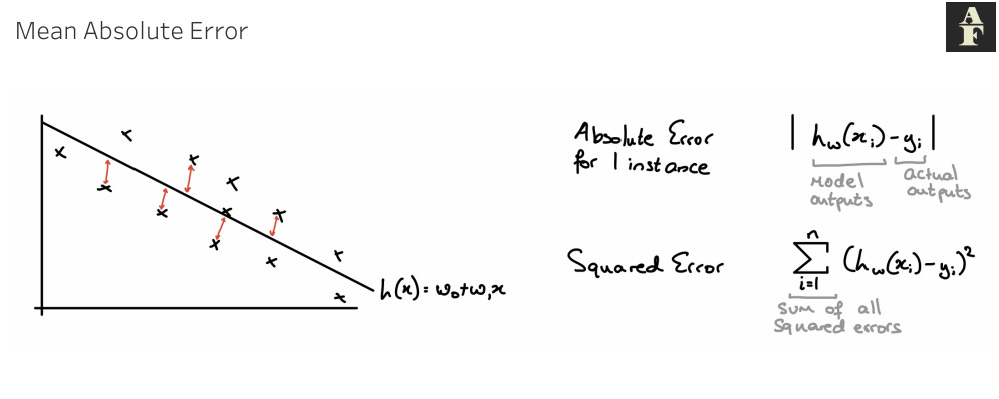
In the diagram above, we have drawn an estimation line that is completely determined by its weights. To calculate the absolute error for one instance, we calculate the absolute difference between our datapoint and its vertical distance to the estimation line, which is its estimated value.
In order to convert this into a performance metric, we look at the squared error, which modifies the concept of the absolute error, turning it into a measure we can apply to our entire dataset. To calculate the squared error, we sum the squared differences of our estimated value and the actual value.
The usage of the square becomes very important later on when we look at algorithms that find the best weight combinations. Algorithms such as Gradient Descent, the most commonly used optimisation algorithm, requires the performance function to be differentiable and this squared error function satisfies that requirement.
So we have the squared error, which takes the idea of our absolute error and applies it to our entire dataset. We now need to turn this into a cost function that will serve as the objective of our model.
So we should remind ourselves what we are looking for in a cost function here and how this relates to linear regression. We want a function that provides us with an idea of how bad our model is in estimating our dataset. With this objective, we are then looking to minimise this function, as the smaller the value the “less-bad” our model is.
To produce this, we adapt our squared error into a mean squared error that helps us estimate our model across the entire dataset. We divide the squared error by 2n because of the presence of our squared term. Since 1/2 is a constant, we do not alter the information the cost function gives us by including this, but we have a cleaner result when differentiating this in weight optimisation algorithms.

Most datasets in the real world will incorporate much more than one variable, so whilst univariate linear regression is our essential foundation, its principles are used to build more complex functions with more than one variable, a model we call multivariate linear regression.
Multivariate Linear Regression
Multivariate linear regression can be split into two different types — with a first order polynomial or with a higher order polynomial.
The order of a function is the greatest power term that that function contains e.g. a polynomial of order two will contain an x² term and no terms with a higher order, a polynomial of order 3 will contain an x³ term and no terms with a higher order.
In multivariate linear regression with a first order polynomial, our model is the sum of the product of each feature with a weight term. This is essentially a continuation of sorts of our univariate function.
The function is as follows:
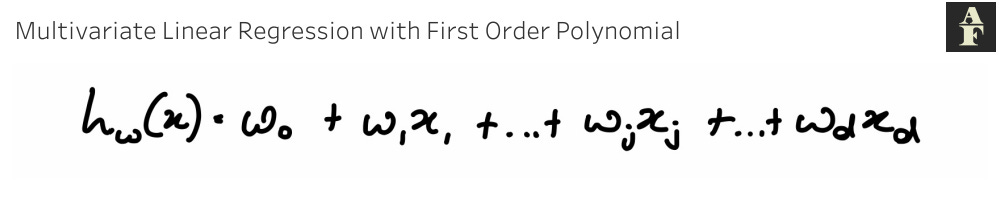
Degrees of freedom are the number of variables that we/the model has the opportunity to change to fit the data better.
This is a useful metric to be aware of as we go forward, because there is a trade off with the number of degrees of freedom we have. More degrees freedom does mean more control over the outputs and affords us a greater amount of flexibility and adaptability, but this also increases the number of combinations of weights and subsequently training time will increase too. We might be able to adjust to a wider range of scenarios with more degrees of freedom, but we have to decide whether this is worth it considering the intensity it requires to calculate.
The first order polynomial model has d+1 degrees of freedom, where d is the dimensionality of the feature vectors as defined before.
The second type of multivariate linear regression is with a higher order polynomial. This is a polynomial in which the order is greater than 1. The higher order polynomial offers a function with more complexity than the single order one.

This equation has k*d+1 degrees of freedom, where k is the order of the polynomial. Below is an example for deriving a polynomial function of order 2 with a training set of 3 features.

Finding the best combination of weights
One method we could use to find the best combination of weights is brute force. Brute force essentially iterates through every single possible combination of weights, calculates our cost function when those weights are used and then moves onto the next combination. After all combinations are tried, the weights that return the lowest cost function are then used. This is a method that is guaranteed to find the best combination, what we call the global minima, but the time it takes to converge to the this combination rises exponentially as the number of degrees of freedom rises.
The main method used to find the best combination of weights is gradient descent. Gradient Descent uses the following procedure:
Start with some initial values for our weights w0, w1, …, wn
We keep updating our weights to reduce our cost function J(w0, w1, …, wn)
Stop when we have reached the minimum

Stage 2 of the gradient descent algorithm, the equation for which is in the image above, shows us exactly why we need our cost function to be differentiable. The algorithm we iterate over takes our current weight and subtracts from it the differentiated cost function multiplied by what is called a learning rate. The size of the learning rate will determine how quickly we converge to or diverge from the minimum value.

So since our cost function has a squared term, we know it takes the shape of a second order polynomial, so essentially a U-shape. By differentiating the cost function at each step of our gradient descent algorithm, we can find out the gradient of the point at which our cost function is at presently. Knowing that our optimal value, or the lowest possible cost value occurs at a gradient of 0, we now know which direction we need to travel in order to ensure we are consistently moving towards this value. At each iteration therefore, we move slightly closer to this combination of weights that return our minimum cost value.
Learning Functions
In gradient descent, during one iteration, we update all of our weights at the same time.
The learning rate dictates how quickly we reach the minimum value. There is a trade off however, in the learning rate that we set. We want a learning rate that isn’t too low, because it will take a long time to find the optimal value. A learning rate too high however, and our function might diverge, never actually reaching the optimal value. We need to find a value that will converge at the correct rate.
There’s no hard and fast rule for setting a learning rate. Typically it is determined by iteratively running through multiple models, each with a different learning rate and selecting the one you are most satisfied with. Typically though, a learning rate ranges from 0.001 to 0.1.