
ML 101 - Linear Classification


This is article #3 in the “ML 101” series, the purpose of which is to discuss the fundamental concepts of Machine Learning. I want to ensure that all the concepts I might use in the future are clearly defined and explained. One of the most significant issues with the adoption of Machine Learning into the field of finance is the concept of a “black box.” There’s a lot of ambiguity about what happens behind the scenes in many of these models, so I am hoping that, in taking a deep-dive into the theory, we can help dispel some worries we might have about trusting these models.
Linear Decision Boundaries
A linear classifier is a model that makes a decision to categories a set of data points to a discrete class based on a linear combination of its explanatory variables. As an example, combining details about a dog such as weight, height, colour and other features would be used by a model to decide its species. The effectiveness of these models lie in their ability to find this mathematical combination of features that groups data points together when they have the same class and separate them when they have different classes, providing us with clear boundaries for how to classify.
If each instance belongs to one and only one class, then our input data can be divided into decision regions separated by decision boundaries.
Although each instance represents a unique attribute, we can consider each instance as being a point in a d-dimensional space, where each individual feature is a dimension on its own and d therefore represents the number of features in our dataset. An instance with 4 features will therefore have its own unique point in a 4 dimensional space for example.
We can create linear decision boundaries to split our classes and use these to then predict the class of new data points. Linear decision boundaries are linear functions of x. They are D-1 dimensional hyperplanes in a D dimensional input space. For example, a set of 3 dimensional features will have 2D decision boundaries (planes) and a set of 2 dimensional features will have 1D decision boundaries (lines).
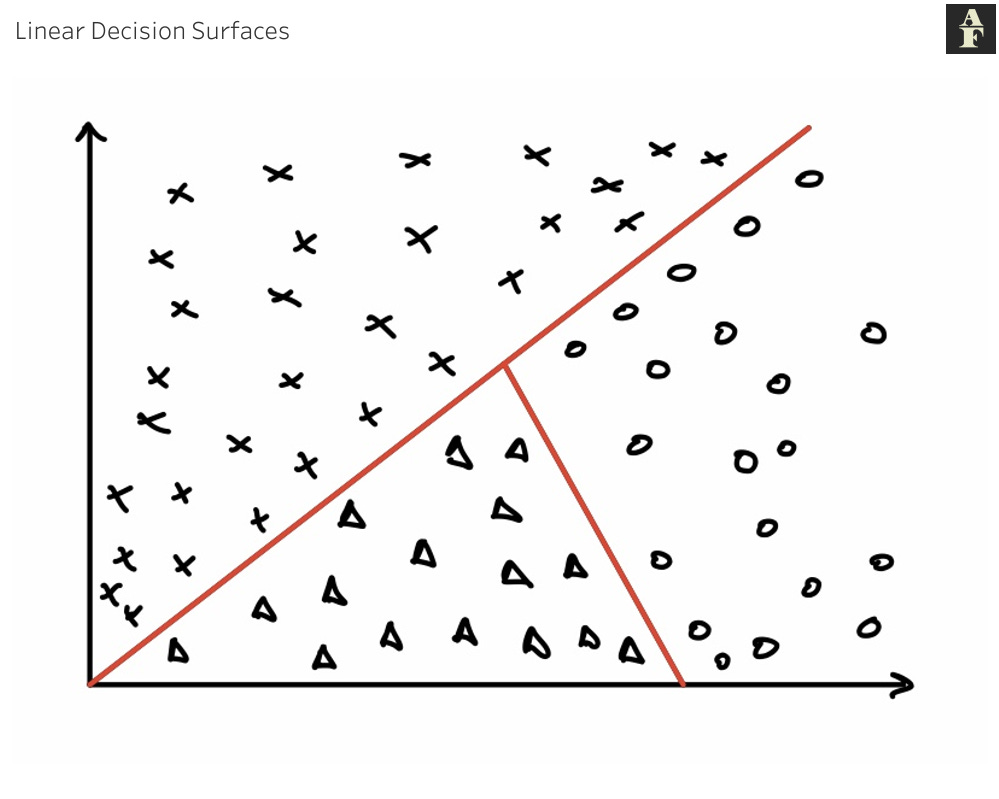
Linear separability is how we define the decision surfaces that our model creates on our data. If our data is linearly separable, then individual classes can be separated by linear decision boundaries, like in the example we have above for a 2D input space.

If decision surfaces are not linearly separable, the decision surfaces may take the form of more complex functions.
The third situation is where our data is not separable at all, through either linear or non linear decision surfaces. If the input data we have is not separable at all, this will generally lead to poor performance from simple machine learning methods, because this concept is what they need to generate accurate predictions. Models need to be able to find a feature or combination of features in your dataset that, when combined in a specific way, allow the model to understand how the classes can be separated based on their attributes.
Mathematically, we can define our classes as follows


Linear Classification is initially an extension of our Linear Regression model. We are aiming to find a set of coefficients for our features that when summed together, will provide us with an accurate measure of our target variable. It is however at this point that a standard linear regression might break down for the purposes of classification. The result of the output is unbounded and therefore makes it very difficult for us to establish any thresholds that we can use to differentiate classes. Linear Classification solves this by introducing the concept of a non linear activation function, that we will pass our regression output into. This function will constrict any value to a certain range, generally (0,1) or (-1,1). This makes it far easier for us to generate decision boundaries to determine classes. For example, if our activation function constricted our range to (0,1) and we have a binary classification problems (two possible classes), then any returned value less than 0.5 would be classified as belonging to class 0 and therefore any value 0.5 and greater would be classified into class 1. We detail the notation for this and the visual representation of our classification functions below.


The decision boundary can be seen as a part in our input space in which h(x) is constant and exactly 0.5 for our (0,1) classes.
Discriminant Functions for Multi-Class Classification
Discriminant functions classify an input provided into one of the defined groups. They use our linear classification models, combined with our decision functions, to determine which class the input should be assigned to.
Linear discriminant functions also extend to multi-class classification. We have two options for carrying out multi-class classification.
The One v All method produces K binary classifiers, where K is the number of individual classes. For each classifier, the 0 class will always be that the data is not part of the 1 class, even though it could be part of multiple classes. e.g. in a 3 class problem, our first classifier will split the classes as follows
C1 — input belong to class 1
C2 — input does not belong to class 1
The idea is that for each instance, only one of the classifiers will return class C1 and if this is the case, then we assign the instance to that class. If more than one classifier returns 1, separate protocols will have to be defined, potentially based on probability, for which class will be used to classify the instance.
The One v One method produces K(K-1)/2 binary classifiers. Each time, we will assign one class as the 0 class and another as the 1 class. We do this for all class combinations and selected the class that returns the highest probability by a majority vote.

Least Squares
The goal of our training our linear discriminant functions is to find the optimum set of weights such that a cost function is minimised.
The least squares method attempts to optimise a decision boundary by minimising the sum of the square of the residuals, defined as the vertical distance between each instance and the best fit line. The greater the residuals, the worse the line has fit to the data we have provided, so the least squares method will continually iterate and adjust the line until the sum of the squared residuals cannot be made smaller.

The benefits of this method for finding a decision boundary are the simplicity and wide applicability. Disadvantages include difficulty to adjust to a multi class problem, because a single line and subsequent residuals now can’t be used as we have more than 2 classes and sensitivity to outliers, since a high residual value will sway the line of best fit in a certain direction.
K-Nearest Neighbors
The k-Nearest Neighbors algorithm is one of the easiest classification algorithms to implement and gain insights from. In a nutshell, the kNN algorithm will take an unseen datapoint, plot it on an N-dimensional space and observe the classes of the k nearest data points to our unseen point. The majority class of the k nearest neighbours will then be assigned to our new unseen point. Visually, we can see the graphical representation of this algorithm below, for k = 7, for which we assign to the unseen data point the class green.

Choosing the right value for k is a key part of this algorithm. Usually, it is best advised to take an iterative approach, where we run this algorithm with many values of k and choose the one that returns the best accuracy on our unseen dataset. It is also advisable to choose an odd number for k, so that we always have a tiebreak when choosing the majority class.
One value to consider is that as we reduce the value of k, our results might become less reliable. Logically, we know that if we use less data points, our representation of the entire composition of seen values is lower and we may encounter situations in which the closest few data points belong to one class, but these are outliers in the actual dataset and the many of the surrounding data points might belong to other classes.
To an extent, increasing the value of k provides our model with more stability. It allows our model to study more values and get a better representation of the composition and positioning of data points. As mentioned, this is true up to a certain point, where the consideration of too many neighbours might distort our outputs. We want to look at neighbours that are reasonably close to our unseen data value and by setting k too high, we might be including data points that don’t actually share any hidden relationships or commonalities with our unseen value.