


A Detailed Look at the Difference Between Lasso and Ridge Regression


We left the last article on linear regression by introducing 2 variations of the standard Ordinary Least Squares (OLS) method, Lasso and Ridge, that have a very subtle difference on paper to distinguish them. As a reminder, the difference is in the type of loss carried out by the penalty parameter, where in Ridge regression we employ an L2 loss which involves squaring the parameters, whilst Lasso employs the L1 loss, which just uses their absolute values.


The distinction, whilst appearing subtle, has significant effects on the resulting coefficient values. Both models cause the coefficients of our parameters to shrink towards 0, since our engine now has to balance the loss function with the size of each parameter. The lasso model however, doesn’t just shrink coefficients towards 0, but actually sets many equal to 0 and can therefore function as a form of feature selection as well.
This article will look into why this phenomenon occurs.
L1 vs L2 Regularization
As we’ve just mentioned, we can categorise each model by how it incorporates the penalty parameter. For the Ridge model, we call this an L2 regularisation method, whilst the Lasso is an L1 regularisation. Regularization can technically be calculated up to L-inf, but for simplicity and interpretability, the L1 and L2 methods are the most common.
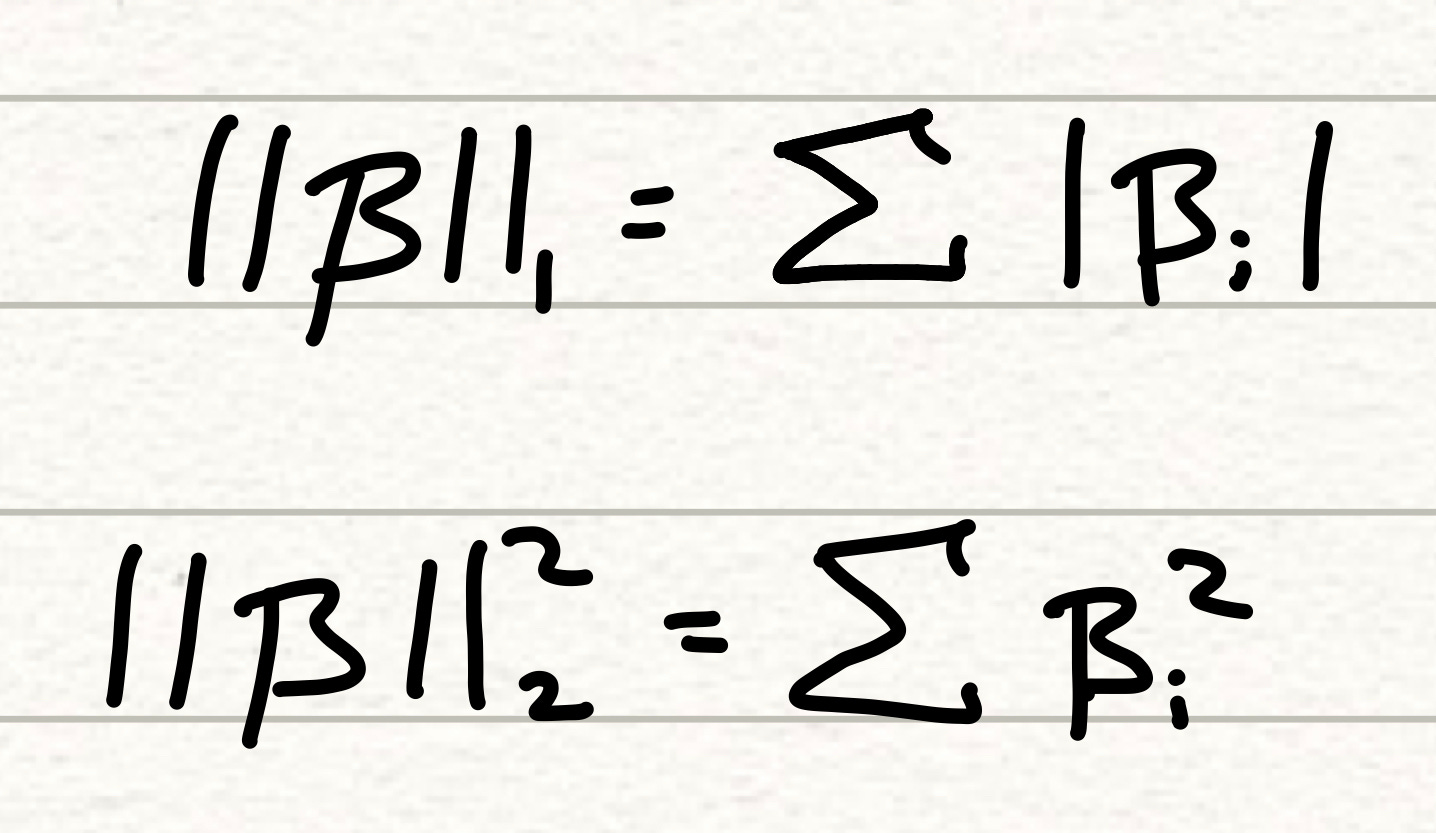
The diagram above, show the calculation of these terms. The L1 term is calculation as a sum of the absolute values of the coefficients, whilst the squared L2 term is calculated as the sum of the squares of the coefficient terms. Note that the standard L2 term is the square root of this entire calculation.
This leads to the expansion of our Lasso and Ridge loss functions as follows,
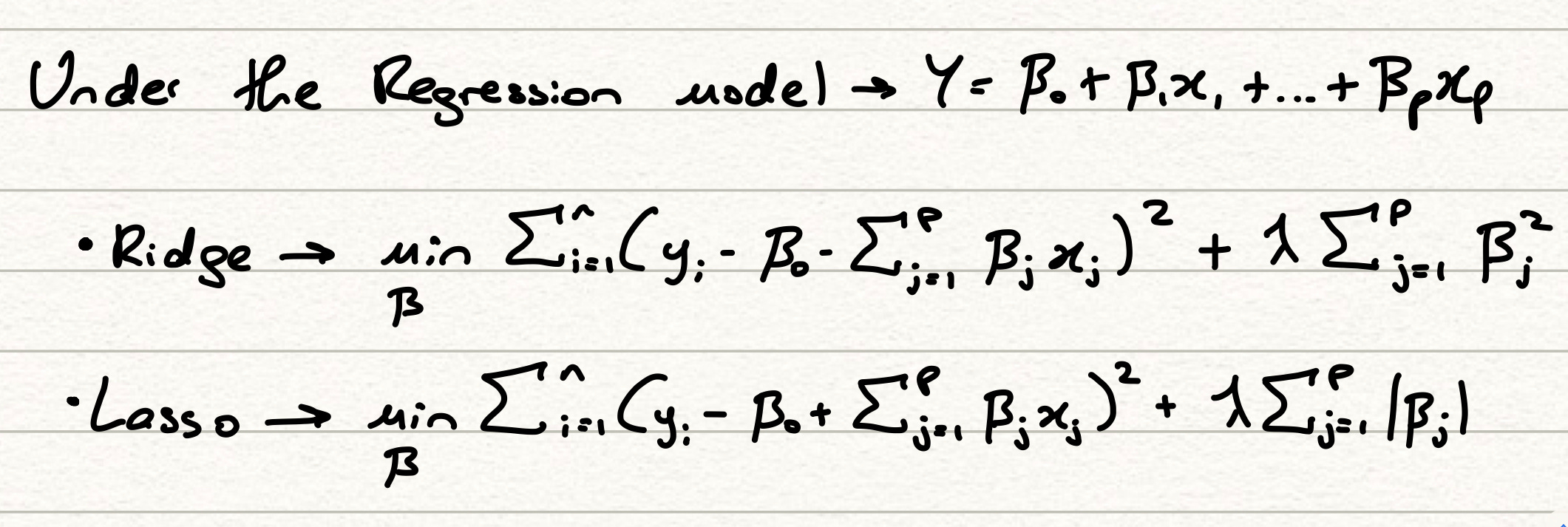
An alternative representation of the above formulas will help us realise the nature of our penalty terms. Consider what we’re doing here -> we’re trying to find the combination of coefficients that lead to the minimum OLS error and a linear function of the sum of the coefficients themselves. We can rewrite this as a constrained optimisation problem, where we try to minimise the OLS error, subject to our parameters being less than a predetermined threshold value. The formulation is shown below.
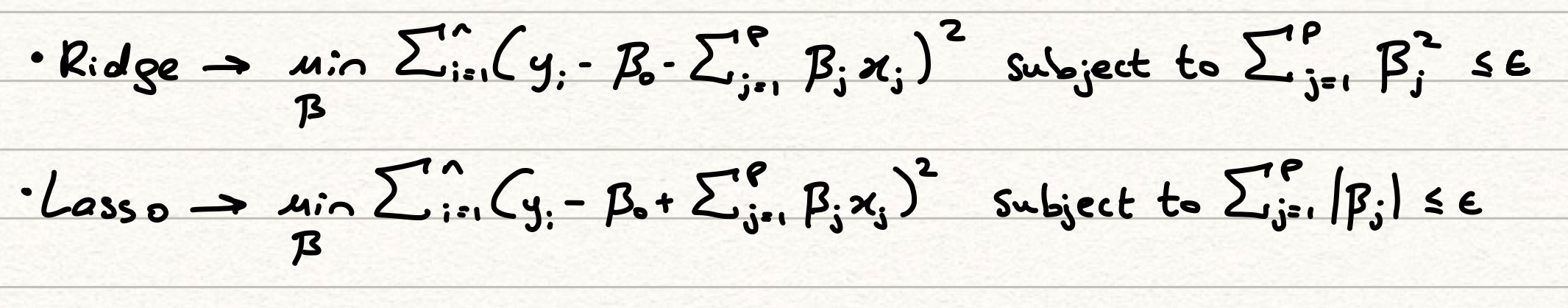
For clarity, we’ll consider the case with just two beta parameters. Specifically, we want to look at how our constraint terms behave, because they are the distinction between the two models here.
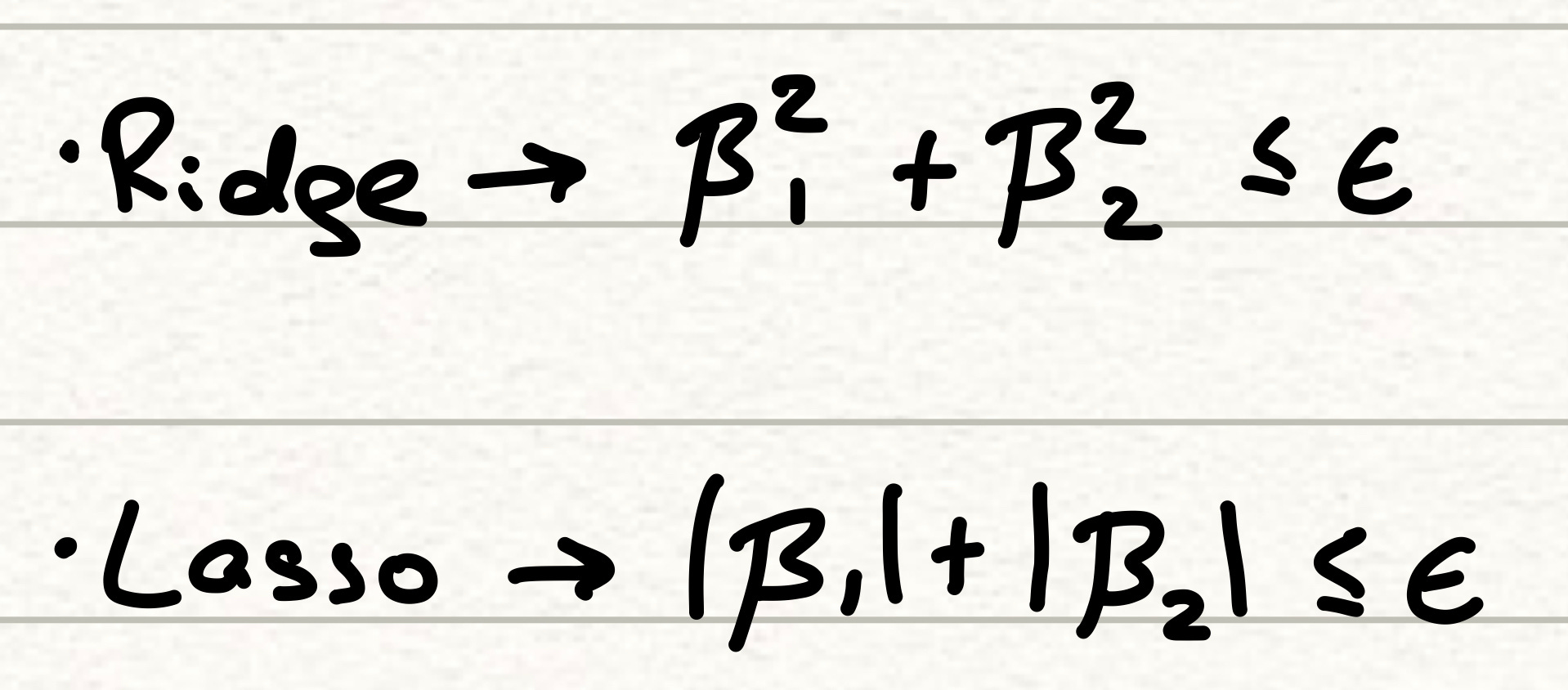
We’re almost there in our understanding of Lasso and Ridge. Clearly the difference between the two models when expanded is how they constrain the space within which our solution can exist. Keeping with this two coefficient example, the graph of these two models show that their difference is in the shape of the constrained boundary that they produce.
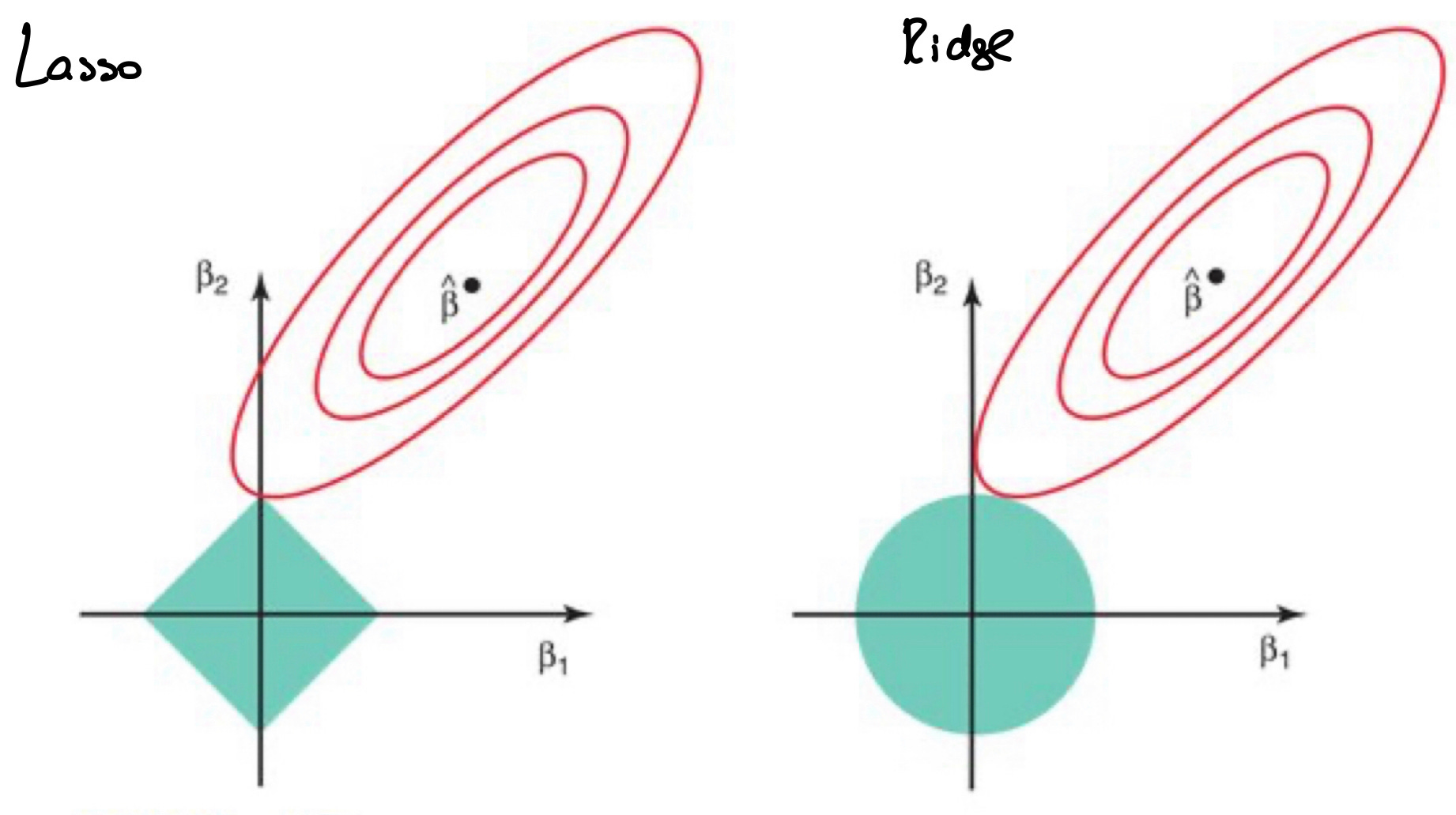
The beta_hat in the above diagram is our optimal coefficient combination, the combination that will be returned by the OLS model. The shaded region is the our constrained formula and these shapes will become larger as our e value increases in the constrained formula. The constraint regions in Lasso clearly have sharp edges, whilst in Ridge, the constrained regions are circular, as dictated by the formulas.
The ellipses surrounding the beta_hat are regions of constant, increasing loss. Given that our models need to find the minimum loss whilst ensuring that they are within (or on) the constrained regions, we can see the point of contact between the each 3rd ellipsis and the shaded region as the coefficient combination that our models will return.
It’s clearer now to see the difference between the two models and specifically how, whilst both models shrink the coefficients, why Lasso reduces some to exactly zero as opposed to close to zero. Due to the sharp edges of the Lasso shaded region, the optimal beta_2 value is 0 and beta_1 is close to zero (or closer to zero than the OLS value). The Ridge model however is circular and the point of contact returns a smaller beta_1 and beta_2 value, but neither of which are equal to exactly zero.
This is one of the reasons why data scientists use the Lasso model directly as a feature selection tool. The Lasso model can inform you of which features are important and which aren’t. It does this clearly by setting low-influential feature coefficients to zero and we can run a second iteration of a model that excludes these features. This is an important consideration in predictive modelling as where possible, we want to keep our models as simple as we can and we definitely don’t want to include features that are going to more of a distraction than an actual benefit.
I have exciting news to share: You can now read Algo Fin in the new Substack app for iPhone.

With the app, you’ll have a dedicated Inbox for my Substack and any others you subscribe to. New posts will never get lost in your email filters, or stuck in spam. Longer posts will never cut-off by your email app. Comments and rich media will all work seamlessly. Overall, it’s a big upgrade to the reading experience.
The Substack app is currently available for iOS. If you don’t have an Apple device, you can join the Android waitlist here.